

Le webinaire
Un matin d'avril, je tombe sur un webinaire de l'agence Empirik "Le SEO chirurgical grâce à la data". Une partie du webinaire m'intéresse particulièrement, un concept nommé par Sylvain Peyronnet : "l'homogénéité sémantique". Le constat est simple, pour ranker sur une thématique, la majorité de ton contenu doit traiter de cette thématique.
Pas en nombre de pages. En trafic.
L'exemple est limpide. Un assureur auto commence à publier sur son blog des articles sur la mécanique. Comment changer ses pneus. La pression des pneumatiques. La courroie de distribution. Ces articles marchent. Le trafic monte. Sauf que Google finit par percevoir le site comme un média automobile, plus comme un assureur. Les positions sur les mots-clés business s'effondrent. Le trafic TOFU a mangé le BOFU.
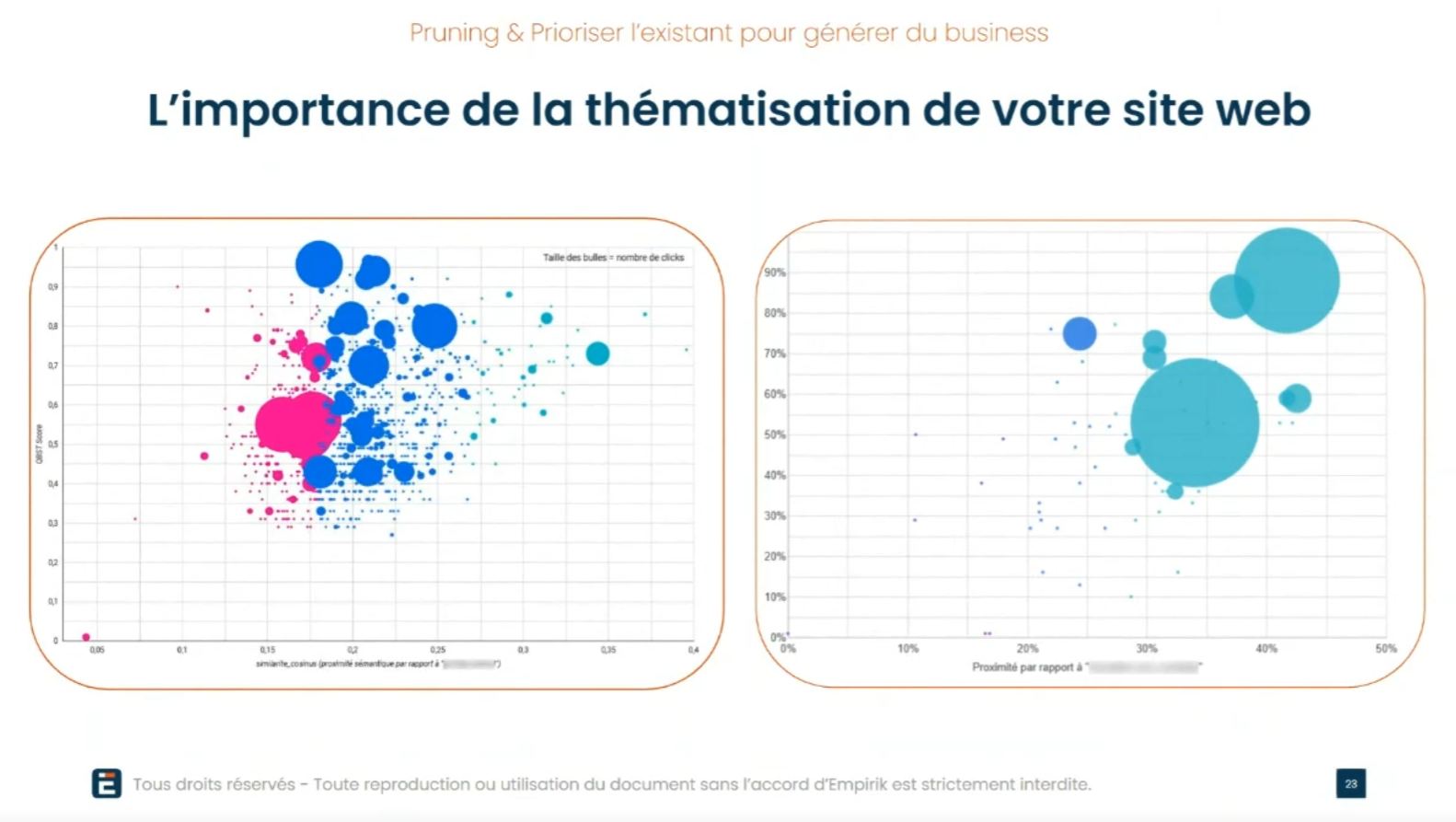
L'intervenant montre un graphe. Des bulles. Deux axes. En abscisse, la similarité avec la thématique visée. En ordonnée, la similarité avec le centroïde du site. La taille des bulles, c'est les clics GSC. Quatre quadrants. En haut à droite, les pages cœur. En haut à gauche, la dilution. En bas à droite, le business isolé. En bas à gauche, les outliers.
Le premier prototype
Le principe est simple sur le papier : crawler un site, transformer chaque page en vecteur, mesurer la distance entre chaque page et la thématique business, visualiser le tout.
Transformer du texte en vecteur, c'est le travail d'un modèle d'embeddings. En l'occurrence, OpenAI text-embedding-3-small. Tu lui donnes un texte, il te retourne une liste de 1536 nombres. C'est comme décrire un vin avec des notes de dégustation : acidité, sucre, tanins. Sauf qu'au lieu de 3 caractéristiques, le modèle en utilise 1536.
Chaque nombre capture un aspect du sens du texte. Le modèle les a appris tout seul en lisant des milliards de pages. On ne sait pas exactement ce que mesure la dimension 847, mais on sait que deux textes qui parlent du même sujet auront des nombres similaires aux mêmes endroits.
Chaque page du site devient un point dans un espace à 1536 dimensions.
Et pour mesurer si deux points sont proches, on utilise la similarité cosinus. C'est la mesure de l'angle entre deux vecteurs. Pas la distance, l'angle. Un texte de 200 mots et un texte de 5000 mots qui disent la même chose auront le même angle, donc le même score. C'est ce qui rend la mesure fiable indépendamment de la longueur des pages.
La formule tient en une ligne :
similarité = produit scalaire(A, B) / (longueur(A) × longueur(B))
Le produit scalaire c'est l'opération de base : on multiplie les 1536 paires de dimensions entre elles et on additionne tout. Les longueurs au dénominateur, c'est ce qui rend la mesure indépendante de la taille du texte. On ne mesure que la direction, pas le volume. Le résultat est entre 0 et 1. Plus c'est proche de 1, plus les textes pointent dans la même direction sémantique.
Je lance Claude Code. FastAPI en backend, React en frontend, Docker pour le déploiement. Le crawler tourne, les embeddings se calculent, le graphe s'affiche. En quelques heures, j'ai un premier résultat sur pyx4.com, le site de la boîte où je travaille.
Le résultat est illisible.
Les bulles sont minuscules. Le graphe est compressé dans un carré de 20% de la surface disponible. Toutes les pages s'empilent entre 0.5 et 0.7 sur les deux axes. On ne distingue rien. On ne comprend rien.
Le problème du spread
C'est un effet connu des embeddings. Dans un espace à 1536 dimensions, tout est vaguement proche de tout. La page sur la cartographie des processus et la page sur les mentions légales du même site ne descendent pas en dessous de 0.45. Et entre deux pages qui parlent de sujets connexes, la différence se joue dans une plage de 0.2. Toute l'information utile est compressée dans un mouchoir de poche.
Ma première réaction, c'est de changer de méthode. Dans le webinaire, l'intervenant mentionne TF-IDF. L'ancienne école. Au lieu de capturer le sens, le TF-IDF compte les mots. Combien de fois "processus" apparaît dans ta page, pondéré par sa rareté dans l'ensemble du corpus. L'avantage : les scores s'étalent naturellement sur une plage plus large. Le graphe respirerait.
Je bascule. L'axe X passe en TF-IDF. Les scores s'étalent un peu. Mais quelque chose ne colle pas.
Mes 21 mots-clés business concaténés font un document de 20 mots. Les pages du site en font 1000. Le TF-IDF compare un confetti à un roman. Les vecteurs sont tellement disproportionnés que les scores ne veulent plus rien dire.
Je pourrais enrichir l'anchor avec un texte généré par GPT, mais c'est un intermédiaire non-déterministe qui change à chaque appel. Et avec 3 gammes de produits différentes, le modèle mélange tout en un seul brouet.
Je cherche sur le web ce que font les gens qui font ça sérieusement.
Le retour en arrière
Mike King, iPullRank. Une référence sur le content pruning. Sa méthode est explicite, et elle tue le débat : le TF-IDF ne reflète pas la façon dont Google détermine la pertinence aujourd'hui.
Sa méthode : embed chaque keyword individuellement, calculer la moyenne des embeddings pour obtenir un centroïde thématique, embed chaque page, similarité cosinus page vs centroïde.
C'est exactement ce que j'avais dans mon premier prototype. Avant de tout casser.
Le problème de compression ne se résout pas en changeant de méthode. Il se résout avec une normalisation min-max. Le principe est bête : tu prends le score le plus bas du projet, il devient 0%. Le plus haut, 100%. Tout le reste s'étale proportionnellement.
score normalisé = (score - minimum) / (maximum - minimum)
Si les scores bruts vont de 0.52 à 0.89, le 0.52 devient 0% et le 0.89 devient 100%. Un score brut de 0.70 donne (0.70 - 0.52) / (0.89 - 0.52) = 49%. L'ordre ne change pas, l'échelle oui.
Je reviens aux embeddings purs sur les deux axes. Je drop scikit-learn. Je drop le TF-IDF.
Les deux axes
Le graphe final mesure deux choses pour chaque page.
L'axe X, c'est la proximité avec la thématique visée. Je prends mes 21 mots-clés BOFU, je les transforme chacun en vecteur, et je calcule leur moyenne :
centroïde anchor = moyenne(embedding(keyword 1), embedding(keyword 2), ..., embedding(keyword 21))
Concrètement : pour chaque dimension, on additionne les valeurs des 21 keywords et on divise par 21. On obtient un seul vecteur de 1536 nombres qui se trouve "au milieu" de tous les keywords. C'est le point qui représente "ce que le site devrait être" dans l'espace sémantique. Chaque page est comparée à ce point. Plus le cosinus est élevé, plus la page parle du bon sujet.
L'axe Y, c'est la proximité avec le centroïde du site. Même opération, mais la moyenne porte sur toutes les pages crawlées. Ce point représente "ce que le site est réellement". Son identité sémantique actuelle, telle que la verrait un modèle qui lit tout le contenu d'un coup.
Le croisement donne quatre quadrants. Haut-droite : proche du centroïde et proche de la thématique. C'est le coeur, l'idéal. Haut-gauche : proche du centroïde mais loin de la thématique. C'est la dilution. Ces pages définissent l'identité du site et elles la tirent dans la mauvaise direction. C'est exactement le cas de l'assureur avec ses articles mécanique. Bas-droite : proche de la thématique mais loin du centroïde. Business isolé. La page parle du bon sujet mais elle est seule dans son coin. Bas-gauche : loin de tout. Outlier.
Les bulles
Le graphe fonctionne. Les scores sont fiables. Reste le problème le plus stupide et le plus chronophage de tout le projet : la taille des bulles.
Premier essai. Rayon min 8px, max 40px. Résultat : des confettis.
Deuxième essai. 10-100px, échelle logarithmique. Le log compresse trop. Les pages à 2 clics et les pages à 50 clics ont presque la même taille.
Troisième essai. Passage en racine carrée. La racine carrée compresse les écarts sans les écraser. √600 = 24.5, √2 = 1.4. Le ratio passe de 300x à 17x.
Quatrième essai. Je réalise que la librairie de graphes interprète mes valeurs comme des surfaces, pas des rayons. Mes [20, 120] donnent des rayons réels de 2.5 à 6px. Je corrige.
Cinquième essai. Les grosses bulles débordent du graphe.
Six itérations sur des tailles de cercles en pixels. Six aller-retours. Pour des ronds sur un écran.
Le résultat
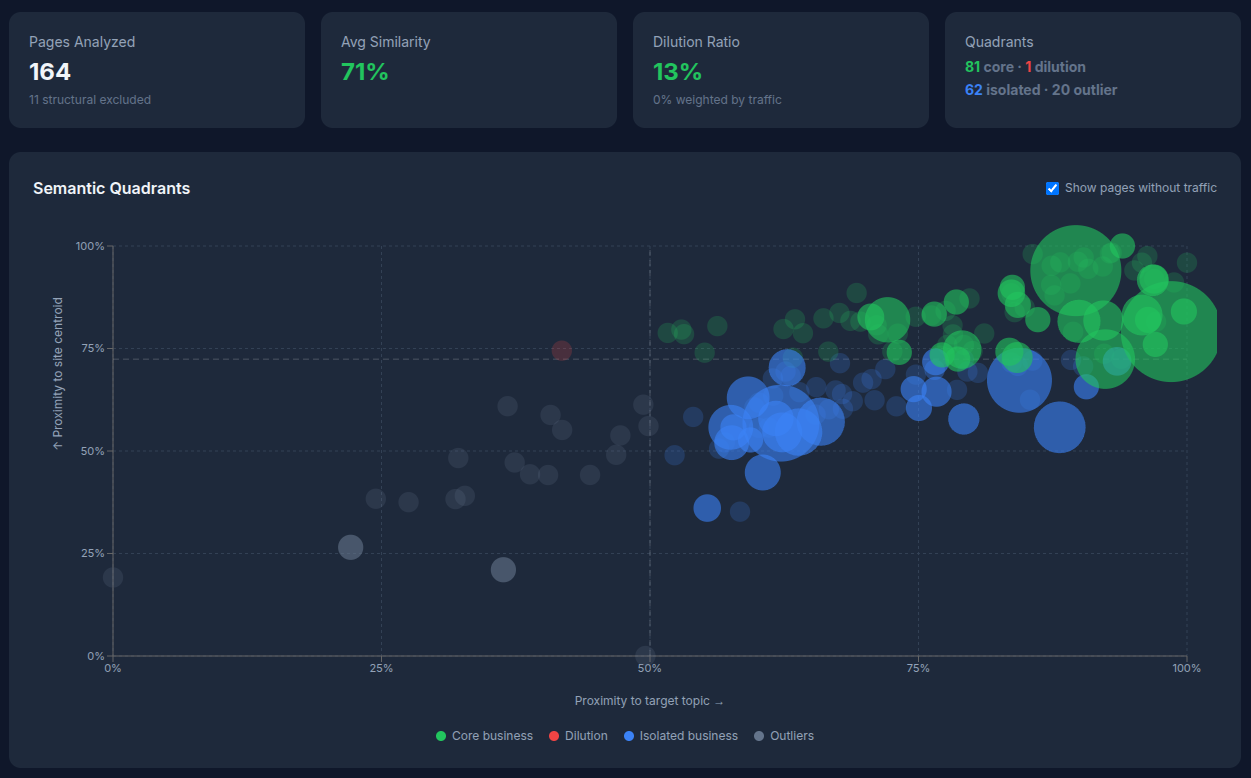
Le graphe final raconte une histoire. Sur pyx4.com, pas de dilution. 3 pages rouges, 0 clics. Le site ne dérive pas. En revanche, 62 pages bleues : des articles de blog qui parlent du bon sujet mais qui vivent dans un monde sémantique séparé des pages produit. Ce sont eux qui captent le trafic. ISO 9001, 315 clics. PDCA, 202. Processus vs procédure, 104. Le trafic entre par le blog et n'a aucun chemin vers les pages qui convertissent.
L'audit du maillage interne confirme : 147 articles de blog sur 293 ne contiennent aucun lien vers une page produit. La moitié du blog est une impasse.
Le plan d'action est simple à écrire, plus long à exécuter. D'abord les balises des pages produit, qui scorent bien en proximité thématique mais dont les titles et meta descriptions ne ciblent aucun mot-clé BOFU. Ensuite le maillage : reprendre les 8 articles à fort trafic qui n'ont aucun lien vers une page produit, puis attaquer les 147 restants par lots.